Créez des sondages en ligne gratuits, en quelques minutes
Posez des questions et prenez des décisions informées grâce au leader mondial des solutions de sondages et de formulaires.
Leader mondial du secteur depuis plus de 20 ans
Plus de 25 millions de questions posées chaque jour
Forte de près de 20 ans d’expérience, notre solution optimisée par l’IA évalue des millions de questions pour produire des sondages et des formulaires toujours plus efficaces.
Plus de 345 000 entreprises dans le monde nous font confiance
Notre plateforme de sondages simple et intuitive permet aux entreprises du monde entier de collecter rapidement les données dont elles ont besoin.
Plus de 17 millions d’utilisateurs actifs
Des millions de personnes utilisent SurveyMonkey dans des entreprises de toutes tailles, dans tous les secteurs d’activité et à tous les stades de développement.
Les plus grandes marques ont choisi SurveyMonkey pour attirer des prospects, fidéliser leurs clients et améliorer l’expérience Employé
Accédez à des centaines de questions préparées par des experts
En quelques secondes, vous pouvez créer un sondage à partir d’un modèle avec des centaines de questions rédigées par des experts. Posez les bonnes questions, minimisez le risque de biais et obtenez rapidement les informations dont vous avez besoin.
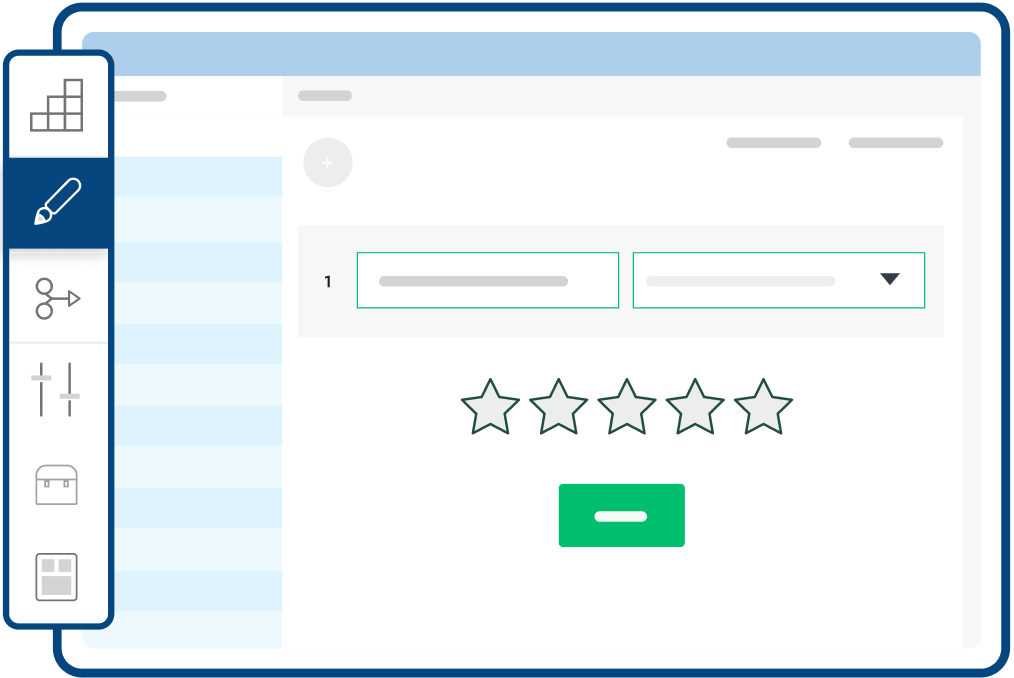

Collectez du feedback de différentes manières
Analysez les attentes de vos clients en recueillant leurs avis via des liens Web, par des sondages ou des formulaires envoyés par email ou incorporés à votre site Web. Nous proposons aussi un panel mondial d’audience pour vous aider à collecter des insights Marché.
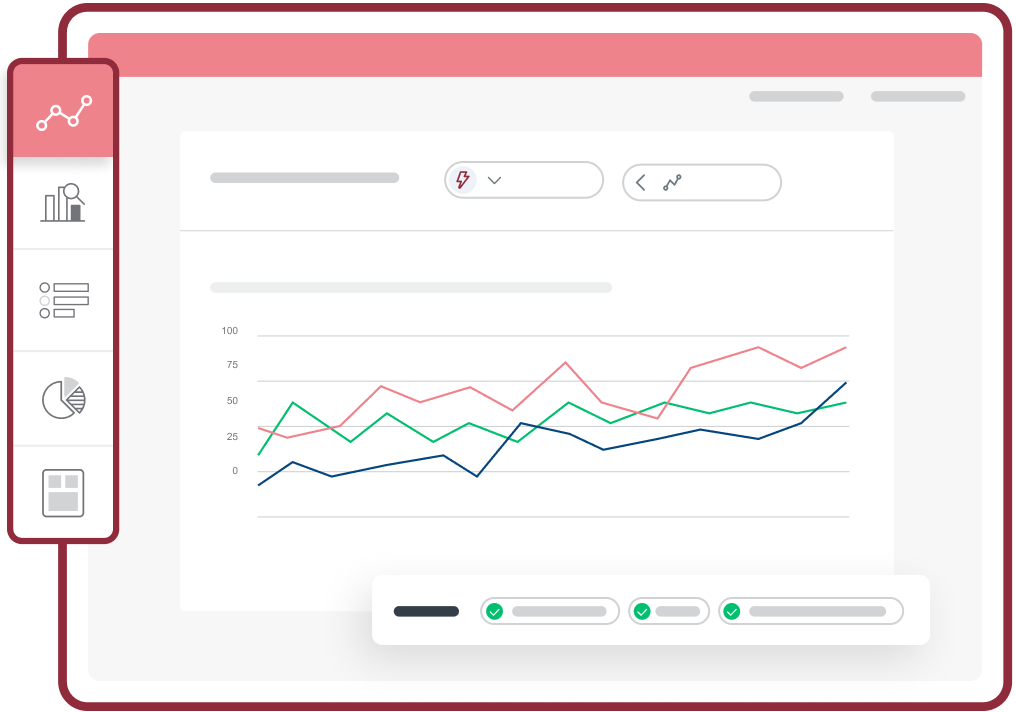
Découvrez rapidement des informations exploitables
Analysez un grand nombre de réponses grâce à des rapports intégrés ou des tableaux de bord avancés, que vous pouvez facilement personnaliser et partager avec votre équipe. Vous pouvez aussi exporter vos données dans votre logiciel préféré pour les étudier plus en détail.
Choisissez l’abonnement qui vous convient
Selon vos besoins, optez pour un abonnement individuel ou un abonnement d'équipe.

Vous cherchez des réponses ciblées à vos sondages ?
Recevez en quelques minutes les réponses dont vous avez besoin avec SurveyMonkey Audience, notre panel mondial de plus de 175 millions de participants.
Commencez avec un modèle de sondage
Inspirez-vous de nos modèles de sondage rédigés par des experts pour créer des sondages et obtenir des réponses pertinentes en un clin d’œil.
Des solutions qui créent des opportunités
Découvrez nos kits d’outils spécialisés, conçus pour votre métier et votre secteur d’activité.

Service client
Améliorez l'expérience de vos clients tout en renforçant l'engagement de vos équipes.

Gestion de produit
Concevez des produits à fort impact, parfaitement adaptés à votre marché cible.


Responsable des ressources humaines
Grâce aux insights, créez des expériences pour faire de vos employés de véritables ambassadeurs de votre marque.

Chef de projet
Obtenez les données dont vous avez besoin pour livrer des projets complexes dans les temps et créer une équipe performante.

Responsable événementiel
Identifiez les éléments clés pour réussir vos événements en respectant vos échéances et votre budget.
Ne vous contentez pas de collecter du feedback. Construisez des expériences marquantes et développez votre activité.
Envie d’aller plus loin ?
Consultez ces ressources supplémentaires pour créer des sondages encore plus performants.

Découvrez nos solutions d’études de marché
Suivez les tendances du marché grâce à nos solutions éprouvées et nos données optimisées par l’IA.

Découvrez d’autres kits d’outils
Découvrez tous nos kits d’outils et apprenez à mieux utiliser les sondages selon votre rôle dans l’entreprise.

Consultez notre Centre d’aide
Découvrez des tutoriels sur nos fonctionnalités et des informations concernant la facturation, contactez le Service client, etc.